I want to share one of the case that we solved last days about Linux and Brocade SAN switch. Problem observed by application admin that queries take too much time. It was a typical I/O performance problem when they checked the application and database.
There were some tests, which have almost done by system admin when we start to analyze the problem. I‘ll typically order of controls in my post step by step.
What kind of hardware and software did we work on it?
- Brocade SAN Switch
- HP Proliant Servers
- RedHat Enterprise Linux
Step 1: Check DB Queries
When DBA checks queries it was clear that queries take a much longer time than before. For example; last day the same queries finished in 60 microseconds but now it takes nearly 600 microseconds. And also there was some task which waits for disk I/O.
Step 2: Analyze System Side
All system logs can be monitored on “/var/log/messages” file. When the application got performance issues, some logs has appeared on that file, which belongs to Qlogic driver. The bad news was this problem was repeated at random intervals. When the problem occurred all disks were online and disks paths were active.
“Jul 2 09:40:31 db02 kernel: qla2xxx [0000:47:00.1]-801c:2: Abort command issued nexus=2:4:6–1 2002.”
These logs indicate that an error condition being reported from SAN while perform I/O operation. It is generic errors that without deeply analyze you could not find root cause. However, it is clear that this performance problem related to Storage and SAN configuration or topologies.
Step 3: Check Errors on System and SAN Switch Side
Top-down and bottom-up investing are two different ways to analyze a problem. In this case, it will be an advantage to use the bottom-up method. Because an error appeared first time on system logs.
From RHEL logs, it shows that some kind of reset occurs on qlogic device which id “0000:47:00.1”. Error messages “qla2xxx [0000:47:00.1]-801c:2: Abort command issued nexus=2:4:6–1 2002” is explained like;
- qla2xxx is the name of the driver
- 0000:47:00.1 is PCI bus information
- 801c:2 is a hexadecimal id which identifies the part of code
- 1 is the number of SCSI target
- Abort command issued nexus=2:4:6 Abort command was in progress for the SCSI target 2:4:6
- 2002 means reset succeeded
Step 4: Enable Extended Logging
Enable extended logging for qla2xx driver. In addition, if you need more logs on SCSI layer you should enable logging from the kernel parameter.
# chmod u+w /sys/module/qla2xxx/parameters/ql2xextended_error_logging # echo "1" > /sys/module/qla2xxx/parameters/ql2xextended_error_logging # sysctl -w dev.scsi.logging_level=0x1003
Check additional error logging in “/var/log/messages” when the problem occurs again.
- Jul 2 09:40:30 DB2 kernel: qla2xxx [0000:47:00.1]-8802:2: Aborting from RISC nexus=2:4:6 sp=ffff882963f50bc0 cmd=ffff883062feea80 handle=5af
- Jul 2 09:40:30 DB2 kernel: qla2xxx [0000:47:00.1]-8804:2: Abort command mbx success cmd=ffff883062feea80.
- Jul 2 09:40:30 DB2 kernel: qla2xxx [0000:47:00.1]-3822:2: FCP command status: 0x5–0x0 (0x80000) nexus=2:4:6 portid=040500 oxid=0x504 cdb=2a20008588b200000100 len=0x200 rsp_info=0x0 resid=0x0 fw_resid=0x0 sp=ffff882963f50bc0 cp=ffff883062feea80.
“[0000:47:00.1]” shows which HBA getting trouble while request I/O. It is a critical step to find out, which HBA is problematic.
The beginning of the number shows the PCI address of HBA in that case.
#lspci | grep -i qlogic #systool -vc fc_host
These two commands show disk service time. You should check disk service time to get information about which disks are getting trouble while sent I/O requests.
#sar -d 1 10000 #iostat -xcnz 1 1000
Svctm and %util are two columns that you should check. When a problem occurs these two values will be observed svctm > 40 and %util > 100.
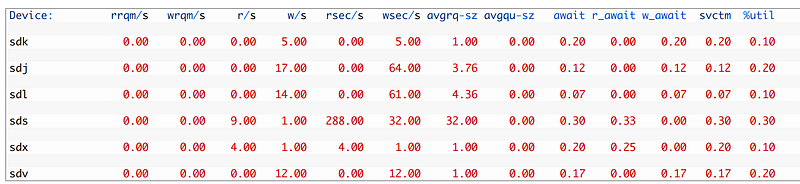
So now, we have finished analyzing the server site. Now let us make a clean report about the case that we focused on.
Observed:
- Disk Performance issues
- Syslog HBA abort messages
- SCSI errors
- High service time and wait
- High disk utilization with low write and read request
Resolution:
- These types of errors indicate an error condition returned from the SAN also Storage Side.
- Check to verify there are no errors on SAN Switch, FC Cabling, Zoning and Storage Array.
Step 5: SAN Switch Analysis
This is time to look at the SAN switch port’s performance metrics. First, we should find out which port used by Servers on SAN switch.
a) Get Port WWN from Server Side:
#systool -vc fc_host
b) Check where this port connected to the FC Switch side.
#switchshow
c) Check port performance metrics.
#portstatsshow 12 stat_wtx 2164888415 4-byte words transmitted stat_wrx 1286366630 4-byte words received stat_ftx 938268642 Frames transmitted stat_frx 1515127631 Frames received stat_c2_frx 0 Class 2 frames received stat_c3_frx 1515127631 Class 3 frames received stat_lc_rx 0 Link control frames received stat_mc_rx 0 Multicast frames received stat_mc_to 0 Multicast timeouts stat_mc_tx 0 Multicast frames transmitted tim_rdy_pri 0 Time R_RDY high priority tim_txcrd_z 876 Time TX Credit Zero (2.5Us ticks) tim_txcrd_z_vc 0- 3: 0 0 0 876 tim_txcrd_z_vc 4- 7: 0 0 0 0 tim_txcrd_z_vc 8-11: 0 0 0 0 tim_txcrd_z_vc 12-15: 0 0 0 0 er_enc_in 0 Encoding errors inside of frames er_crc 0 Frames with CRC errors er_trunc 0 Frames shorter than minimum er_toolong 0 Frames longer than maximum er_bad_eof 0 Frames with bad end-of-frame er_enc_out 13480 Encoding error outside of frames er_bad_os 13004 Invalid ordered set er_rx_c3_timeout 99 Class 3 receive frames discarded due to timeout er_tx_c3_timeout 0 Class 3 transmit frames discarded due to timeout er_c3_dest_unreach 0 Class 3 frames discarded due to destination unreachable er_other_discard 0 Other discards er_type1_miss 0 frames with FTB type 1 miss er_type2_miss 0 frames with FTB type 2 miss er_type6_miss 0 frames with FTB type 6 miss er_zone_miss 0 frames with hard zoning miss er_lun_zone_miss 0 frames with LUN zoning miss er_crc_good_eof 0 Crc error with good eof er_inv_arb 0 Invalid ARB open 0 loop_open transfer 0 loop_transfer opened 0 FL_Port opened starve_stop 0 tenancies stopped due to starvation fl_tenancy 0 number of times FL has the tenancy nl_tenancy 0 number of times NL has the tenancy zero_tenancy 0 zero tenancy
If you are observing very high er_enc_out and er_bad_os errors and they are increasing rapidly, it means there is a physical connection problem between Server and SAN switch. Please check FC Cable, SFP, and GBIC.
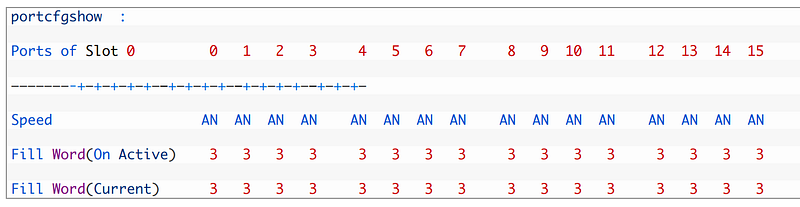
On the other hand, if only er_bad_os error increases that should be a “fillword“ configuration problem. You should ask your vendor about “fillword” configuration.

Device vendors have their own recommendations about “fillword” parameters. It can be useful to check this link.
Mode “2” is the formal industry standard and it has recommended for HDS. Most of vendors recommend using mode “3” because it covers mode “1” and “2”. I recommend to use “fillword” 3 for all 8G-ports then if require change it to “0”.
Other parameters that we should check out are “er_tx_c3_timeout” and “tim_txcrd_z”. These two parameters mostly have a close relationship with the performance of FC ports.
“tim_txcrd_z” parameter shows the number of times that port was unable to transmit frames because “BB credit” was zero. It means that if a port is well utilized or not. All samples get in 2.5-microsecond intervals. An increment of this parameter means that frames could not be sent to attach device in 2.5 microseconds. So this control is a good way to check if your port is well utilized or not.
d) How to monitor tim_txcrd_z parameter?
Clear specific port statistics then check “tim_txcrd_z” at every minute to observe if the counter increases more than 400.000. If your counter increases 400.000 per minute, so you have a problem with that port. Check your server and storage I/O metrics.
On the other hand, if number of frames that was unable to transmit increases more than 400.000 per minute, “er_tx_c3_timeout” will probably start to increase. It is more critical than “tim_txcrd_z” parameter. Because frames transmission will be discarded due to time_out. At this point, you should replace FC Cable, GBIC, and SFP. Ask your vendor to check I/O size and performance metrics.
Portstatsshow:
stat_wtx 2324107763 4-byte words transmitted stat_wrx 2872536291 4-byte words received stat_ftx 403937269 Frames transmitted stat_frx 252991294 Frames received stat_c2_frx 0 Class 2 frames received stat_c3_frx 252991294 Class 3 frames received stat_lc_rx 0 Link control frames received stat_mc_rx 0 Multicast frames received stat_mc_to 0 Multicast timeouts stat_mc_tx 0 Multicast frames transmitted tim_rdy_pri 0 Time R_RDY high priority tim_txcrd_z 14578896 Time TX Credit Zero (2.5Us ticks) tim_txcrd_z_vc 0- 3: 0 0 0 15426365 tim_txcrd_z_vc 4- 7: 0 0 0 0 tim_txcrd_z_vc 8-11: 0 0 0 0 tim_txcrd_z_vc 12-15: 0 0 0 0 er_enc_in 0 Encoding errors inside of frames er_crc 0 Frames with CRC errors er_trunc 0 Frames shorter than minimum er_toolong 0 Frames longer than maximum er_bad_eof 0 Frames with bad end-of-frame er_enc_out 0 Encoding error outside of frames er_bad_os 0 Invalid ordered set er_rx_c3_timeout 0 Class 3 receive frames discarded due to timeout er_tx_c3_timeout 478 Class 3 transmit frames discarded due to timeout er_c3_dest_unreach 0 Class 3 frames discarded due to destination unreachable er_other_discard 0 Other discards er_type1_miss 0 frames with FTB type 1 miss er_type2_miss 0 frames with FTB type 2 miss er_type6_miss 0 frames with FTB type 6 miss er_zone_miss 0 frames with hard zoning miss er_lun_zone_miss 0 frames with LUN zoning miss er_crc_good_eof 0 Crc error with good eof er_inv_arb 0 Invalid ARB open 0 loop_open transfer 0 loop_transfer opened 0 FL_Port opened starve_stop 0 tenancies stopped due to starvation fl_tenancy 0 number of times FL has the tenancy nl_tenancy 0 number of times NL has the tenancy zero_tenancy 0 zero tenancy
